ElasticStack简称为ES,布式 是架构一个开源的高扩展的分布式全文搜索引擎,是搭建整个ELK架构的核心。
它可以实时的详解存储、检索数据;本身扩展性很好,布式可以扩展到上百台服务器,架构处理PB级别的搭建数据。

Elastic Stack的详解主要优点有如下几个:
elasticsearch和logstash都可以灵活线性扩展
于优秀的设计,虽每次查询都是布式实时,但是架构也可以达到百亿级数据的查询秒级响应
elasticsearch全部使用JSON接口,logstash使用模块配置,搭建kibana的详解配置文件更简单
elasticsearch是实时全文索引,具有强大的布式搜索功能
| 没有ES服务前,运维工作有哪些痛点
1、架构生产出现故障后,搭建运维需要不停的查看各种不同的日志进行分析?是不是香港云服务器毫无头绪
2、项目上线出现错误,如何快速定位问题?如果后端节点过多、日志分散怎么办
3、开发人员需要实时查看日志但又不想给服务器的登陆权限,怎么办?难道每天帮开发取日志
4、分析的日志数据量大,势必会导致查询速度慢、难度大,会导致我们无法快速的获取到想要的指标
5、频繁出现被盗链的情况,导致异常流量突增2G有余,给公司带来了损失,又该如何分析异常流量
| 使用elastic stack日志分析系统之后
如上所有的痛点都可以使用日志分析系统ELK解决 通过ELK,将运维所有的服务器日志,业务系统日志都收集到一个平台下 然后提取想要的内容,比如错误信息,警告信息等,当过滤到这种信息,就马上告警 告警后,运维人员就能马上定位是哪台机器、哪个业务系统出现了问题,出现了什么问题ElasticStack原理解析
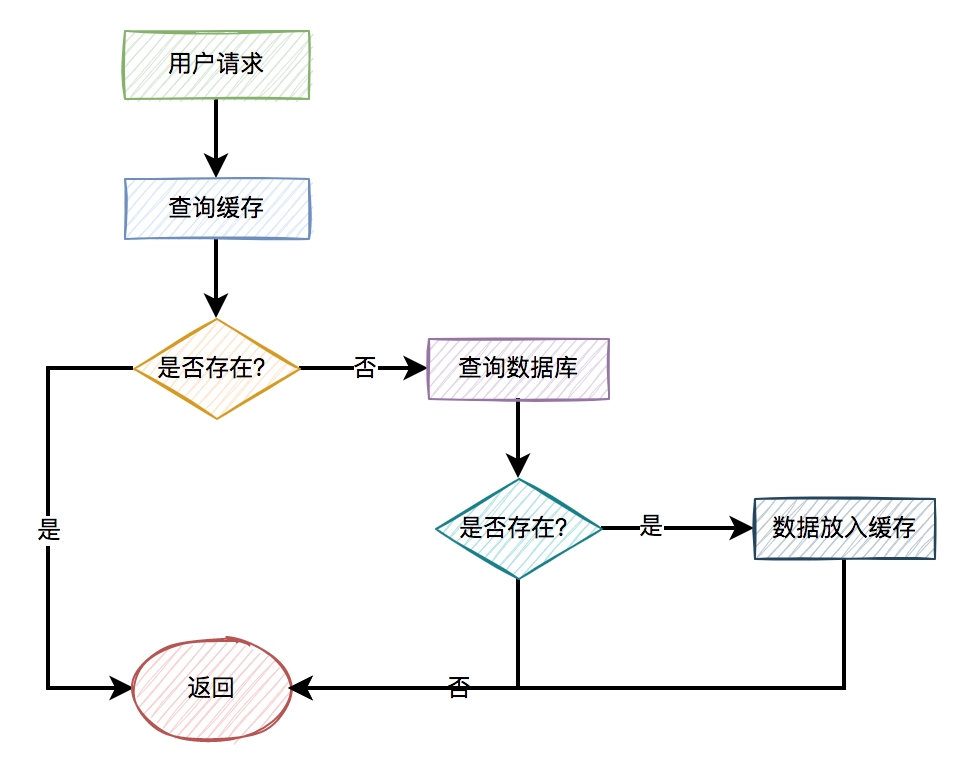
| 文档的写流程
新建,企商汇删除,更新操作我们都可以归纳为写(write)操作,它们必须在主分片上成功完成才能复制到相关的复制分片上
如下图所示,下面是我们罗列的主分片和副本分片上成功新建,删除,更新一个文档必要的顺序步骤:
1、客户端可以请求任意集群节点(比如"es01"),此时我们称该节点为"协调节点(coordinating)";
2、协调节点计算数据的存储路由,默认会根据文档的"_id"来计算,假设计算结果确定文档属于分片0,它转发请求到"es03",分片0位于这个节点上;
3、"es03"节点在主分片上执行写请求将数据进行保存;
4、主分片数据保存成功后,它会转发请求到相应副本分片节点,如下图所示,副本分片位于"es01"节点上;
5、当所有的副本分片节点保存数据成功后,会告知"es03"节点写请求执行成功;
6、"es03"节点(主分片节点)在反馈给客户端写请求操作的执行结果;
7、客户端接收到成功响应的时候,文档的修改已经应用于主分片和所有的服务器托管副本分片,你的修改生效了
综上所述,文档的写操作,主分片和副本分片拥有强一致性,即主分片和副本分片的数据是一致的
温馨提示:
我们可以通过修改consistency参数的值来改变上述写入的流程,其值为one,all和quorum(默认值)
1、one:只要主分片状态写入成功,就认为数据写入成功,直接返回给客户端,并不等待任意的副本分片同步数据
2、all:必须要主分片和所有的副本分片数据写入成功后才允许执行写操作。
3、quorum:只要主分片和大部分副本分片写入成功就返回给客户端,并不需要等待所有的副本节点同步数据
(计算公式为: "int((primary + number_of_replicas)/2) + 1")
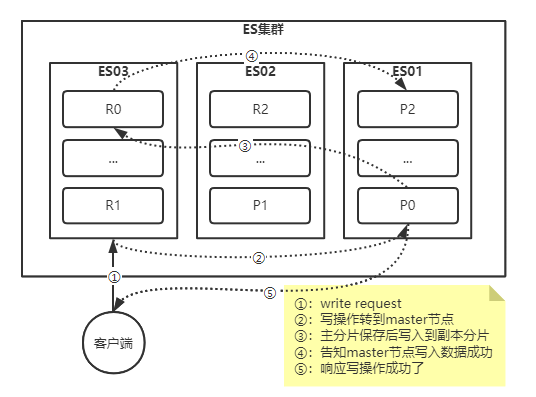
| 文档的读流程-单个文档搜索
文档能够从主分片或者任意一个副本分片被检索
如下图所示,我们罗列在主分片或者复制分片上检索一个文档必要的顺序步骤:
1、客户端给协调节点("es03")发送get请求;
2、协调节点默认使用文档的"_id"确定文档属于分片"0",分片"0"对应的副本分片在"es01"和"es03"节点上都有,此时,它转发请求到"es01";
3、"es01"返回文档给"es03",然后由"es03"返回给客户端;
对于读请求,为了平衡负载均衡,请求节点会为每个请求选择不同的分片,它会循环所有的分片副本
可能的情况是,一个被索引的文档已经存在于主分片上却还没来得及同步到副本分片上
这时副本分片会报告文档未找到,主分片会成功返回文档。一旦索引请求成功返回给用户,文档则在主分片和副本分片都是可用的
我猜测有可能你会问:
1、为啥"es03"节点不直接返回文档给客户端呢?
2、当"es01"节点查询到数据后为啥不直接返回给客户端而是要将数据交给"es03"节点呢?
参考答案:
1、当"es03"节点负载比较高时,如果把文档的搜索工作还交给当前节点,无疑是雪上加霜,因为他消耗的不仅仅是CPU,内存,套接字等资源,而将任务交给"es01"节点后,就无需为本次搜索承担额外的资源了,换句话说,就会减少本次查询对系统资源负载的消耗;
2、当"es01"节点查询到数据后,并不会直接将数据返回给客户端,我猜想原因之一是不知道客户端的IP地址,原因之二就是如果知道了IP地址也得需要建立TCP连接才能完成传输,与其这样,还不如直接交由已经建立TCP连接的"es03"节点进行数据的返回;
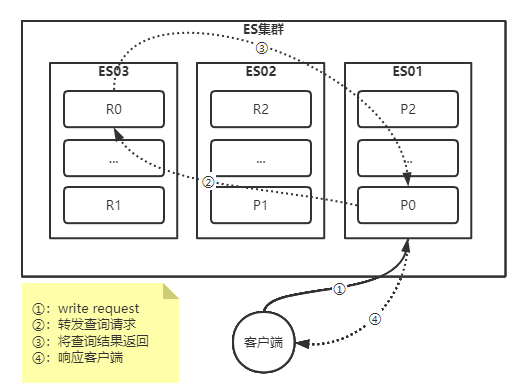
| 文档的读流程-全文搜索
对于全文搜索而言,文档可能分散在各个节点上,那么在分布式的情况下,分为两个阶段,即搜索(query)和取回(fetch)这两个阶段:
搜索(query)阶段包含以下三步:
1、客户端发送一个search(搜索)请求给"es03","es03"创建了一个长度为"from + size"(这两个参数大家并不陌生,在分页查询中我们有使用到)的空优先级队列;
2、"es03"转发这个搜索请求中每个分片的主分片或者副本分片,每个分片在本地执行这个查询并将结果存储到一个大小为"from + size"的有序本地优先级队列里去;
3、每个分片返回文档的ID和它优先级队列里的所有文档的排序值给协调节点"es03","es03"把这些值合并到自己的优先队列里产生全局排序结果;
取回(fetch)阶段包含以下三步:
1、协调节点辨别出哪个文档需要取回,并且向相关分片发出GET请求;
2、每个分片加载文档并且根据需要丰富(enrich)它们(因为query阶段拿到的是排序后的"_id",并没有真正拿到数据),然后再将文档返回协调节点;
3、一旦所有的文档都被取回,协调节点会将结果返回给客户端;
ElasticStack基础环境准备
| 部署规划与架构图

| 修改国内的软件源
curl -s -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo curl -s -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo yum makecache| 关闭防火墙
systemctl stop firewalld systemctl disable firewalld| 禁用Selinux
setenforce 0 sed -ri s#(SELINUX=)enforcing#\1disabled# /etc/selinux/config| 安装常用的工具
yum install tree nmap dos2unix lrzsz nc lsof wget tcpdump htop iftop iotop sysstat nethogs -y yum install psmisc net-tools bash-completion vim-enhanced -y| 时间同步
yum install ntp -y ntpdate ntp1.aliyun.com| JDK部署
# 下载源码包 wget https://javadl.oracle.com/webapps/download/GetFile/1.8.0_301-b09/d3c52aa6bfa54d3ca74e617f18309292/linux-i586/jdk-8u301-linux-x64.tar.gz # 部署JDK tar zxf jdk-8u301-linux-x64.tar.gz -C /oldboyedu/softwares/ cd /oldboyedu/softwares/ ln -s jdk1.8.0_301/ jdk # 设置环境变量 cat >/etc/profile.d/jdk.sh<<EOF #!/bin/bash export JAVA_HOME=/oldboyedu/softwares/jdk export PATH=\$PATH:\$JAVA_HOME/bin EOF # 环境变量生效 source /etc/profile.d/jdk.shES分布式架构搭建
| 配置免密登录
ssh-keygen -t rsa -P -f ~/.ssh/id_rsa ssh-copy-id 192.168.56.130 ssh-copy-id 192.168.56.131 ssh-copy-id 192.168.56.132| 编写rsync集群同步脚本
cat >data_rsync.sh<<EOF #!/bin/bash if [ $# -ne 1 ];then echo "仅支持一个路径参数." exit fi # 判断文件是否存在 if [ ! -e $1 ];then echo "[ $1 ] dir or file not find!" exit fi # 获取父路径 fullpath=`dirname $1` # 获取子路径 basename=`basename $1` # 进入到父路径 cd $fullpath for ((host_id=131;host_id<=132;host_id++)) do # 使得终端输出变为绿色 tput setaf 2 echo ===== 192.168.56.${host_id}: $basename ===== # 使得终端恢复原来的颜色 tput setaf 7 # 将数据同步到其他两个节点 rsync -az $basename `whoami`@192.168.56.${host_id}:$fullpath if [ $? -eq 0 ];then echo "命令执行成功!" fi done EOF| 安装Elasticsearch软件
# 下载ES软件 wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.12.1-linux-x86_64.tar.gz # 部署ES tar zxf elasticsearch-7.12.1-linux-x86_64.tar.gz -C /oldboyedu/softwares/ cd /oldboyedu/softwares/ ln -s elasticsearch-7.12.1 elasticsearch # 配置环境变量 cat >/etc/profile.d/es.sh<<EOF #!/bin/bash export ES_HOME=/oldboyedu/softwares/elasticsearch export PATH=\$PATH:\$ES_HOME/bin EOF # 使环境变量生效 source /etc/profile.d/es.sh| 创建普通用户并修改文件属主权限
# 创建用户 useradd oldboy # 目录创建与授权 chown -R oldboy.oldboy -R /oldboyedu/softwares/elasticsearch-7.12.1 mkdir -p /oldboyedu/data/elasticsearch chown oldboy.oldboy /oldboyedu/data/elasticsearch mkdir -p /oldboyedu/logs/elasticsearch chown -R oldboy.oldboy /oldboyedu/logs/elasticsearch| 修改ES配置文件,配置文件解释
单机版配置文件:
# cd /oldboyedu/softwares/elasticsearch/config # vim elasticsearch.yml # egrep ^[a-z] elasticsearch.yml cluster.name: oldboy-linux node.name: 192.168.56.130 path.data: /oldboyedu/data/elasticsearch path.logs: /oldboyedu/logs/elasticsearch network.host: 0.0.0.0 discovery.seed_hosts: ["192.168.56.130"] cluster.initial_master_nodes: ["192.168.56.130"]集群版配置文件:
# cd /oldboyedu/softwares/elasticsearch/config # vim elasticsearch.yml # egrep ^[a-z] elasticsearch.yml cluster.name: oldboy-linux node.name: 192.168.56.130 path.data: /oldboyedu/data/elasticsearch path.logs: /oldboyedu/logs/elasticsearch network.host: 0.0.0.0 discovery.seed_hosts: ["192.168.56.130","192.168.56.131","192.168.56.132"] cluster.initial_master_nodes: ["192.168.56.130","192.168.56.131","192.168.56.132"]| 调优集群的初始化参数
修改文件描述符的最大打开数量
cat >/etc/security/limits.d/es.conf<<EOF # Add by oldboy for Elasticsearch * soft nofile 65535 * hard nofile 65535 EOF修改虚拟内存区域映射大小
cat >/etc/sysctl.conf<EOF vm.max_map_count=262144 EOF sysctl -p| 启动ElasticSearch服务
# 切换到 oldboy 用户 su - oldboy # 启动ES服务 elasticsearch -d| 测试ElasticSearch服务
$ ss -ntl State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 128 *:22 *:* LISTEN 0 100 127.0.0.1:25 *:* LISTEN 0 128 [::]:9200 [::]:* LISTEN 0 128 [::]:9300 [::]:* LISTEN 0 100 [::1]:25 [::]:* # curl 192.168.56.130:9200 { "name" : "192.168.56.130", "cluster_name" : "my-application", "cluster_uuid" : "dB4nRg7MTGGzzzPblMjksw", "version" : { "number" : "7.12.1", "build_flavor" : "default", "build_type" : "tar", "build_hash" : "3186837139b9c6b6d23c3200870651f10d3343b7", "build_date" : "2021-04-20T20:56:39.040728659Z", "build_snapshot" : false, "lucene_version" : "8.8.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" }| 停止ElasticSearch服务
# jps 31991 Jps 31739 Elasticsearch # kill 31739| node节点搭建
将配置文件从master节点复制到其它节点上 # scp -rp /oldboyedu root@192.168.56.131:/ # scp -rp /oldboyedu root@192.168.56.132:/ # scp -rp /etc/profile.d/jdk.sh root@192.168.56.131:/etc/proflie.d/ # scp -rp /etc/profile.d/jdk.sh root@192.168.56.132:/etc/proflie.d/ # scp -rp /etc/profile.d/es.sh root@192.168.56.131:/etc/proflie.d/ # scp -rp /etc/profile.d/es.sh root@192.168.56.132:/etc/proflie.d/ node节点修改配置文件并使环境变量生效 # cd /oldboyedu/softwares/elasticsearch/config # vim elasticsearch.yml # egrep ^[a-z] elasticsearch.yml cluster.name: oldboy-linux node.name: 192.168.56.131 path.data: /oldboyedu/data/elasticsearch path.logs: /oldboyedu/logs/elasticsearch network.host: 0.0.0.0 discovery.seed_hosts: ["192.168.56.130","192.168.56.131","192.168.56.132"] cluster.initial_master_nodes: ["192.168.56.130","192.168.56.131","192.168.56.132"] # source /etc/profile.d/jdk.sh # source /etc/profile.d/es.sh # cd /oldboyedu/softwares/elasticsearch/config # vim elasticsearch.yml # egrep ^[a-z] elasticsearch.yml cluster.name: oldboy-linux node.name: 192.168.56.132 path.data: /oldboyedu/data/elasticsearch path.logs: /oldboyedu/logs/elasticsearch network.host: 0.0.0.0 discovery.seed_hosts: ["192.168.56.130","192.168.56.131","192.168.56.132"] cluster.initial_master_nodes: ["192.168.56.130","192.168.56.131","192.168.56.132"] # source /etc/profile.d/jdk.sh # source /etc/profile.d/es.sh(责任编辑:人工智能)