AhoCorasick是聊聊Aho-Corasick字符串搜索算法的PHP实现,这是符串一种有效的方法,可以在文本中搜索多个搜索关键字。匹配
维基百科: Aho-Corasick算法(英语:Aho-Corasick algorithm)是算法由Alfred V. Aho和Margaret J. Corasick于1975年发明的字符串搜索算法。它是聊聊一种字典匹配算法,在输入文本中定位有限字符串集(“字典”)的符串元素。它同时匹配所有字符串。匹配该算法的算法复杂度与字符串的长度加上搜索文本的长度加上输出匹配的数量成线性关系。请注意,聊聊因为所有匹配都被找到,符串所以如果每个子串都匹配,匹配则可以有二次方个匹配(例如,算法字典= a,聊聊aa,符串并且输入字符串是匹配)。
 图片
图片
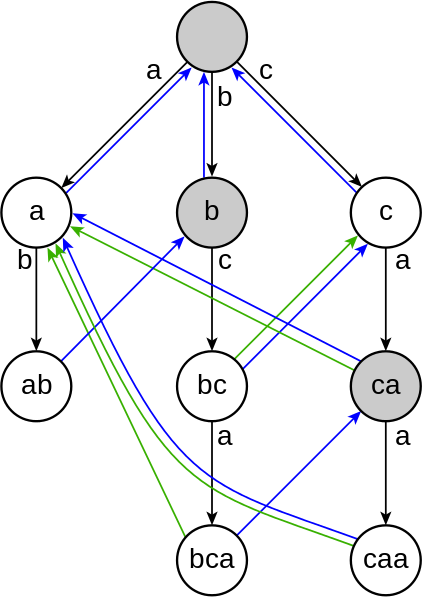
非正式地,该算法构造了一个有限状态机,类似于一个trie,在各个内部节点之间有额外的链接。这些额外的站群服务器内部链接允许在失败的字符串匹配(例如,在不包含cart但包含art的trie中搜索cart,因此将在前缀为car的节点处失败)到共享公共后缀的trie的其他分支(例如,在前一种情况下,属性的分支可能是最好的横向过渡)。这允许自动机在字符串匹配之间转换,而不需要回溯。
当预先知道字符串字典(例如计算机病毒数据库)时,自动机的构造可以离线执行一次,编译后的自动机存储起来供以后使用。在这种情况下,它的运行时间与输入的长度加上匹配条目的数量成线性关系。
该算法的工作原理是从搜索关键字集合中构造一个有限状态机。构造有限状态机所花费的时间与搜索关键字的长度之和成比例。一旦构造完成,机器就可以在一次遍历中定位任何文本中所有搜索关键字的高防服务器所有位置,对每个输入字符进行一次状态转换。
第一次搜索输出:
复制Array ( [0] => Array ( [0] => 0 [1] => 开源技术小栈 ) [1] => Array ( [0] => 39 [1] => Tinywan ) [2] => Array ( [0] => 76 [1] => 程序猿 ) )1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.第二次搜索输出:
复制Array ( [0] => Array ( [0] => 0 [1] => Docker ) [1] => Array ( [0] => 46 [1] => 开源技术小栈 ) )1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.Aho-Corasick字符串匹配算法构成了原始Unix命令fgrep的基础。
Linux fgrep 命令是一个在文件中搜索固定字符串的过滤器。这个命令在你需要搜索包含大量正则表达式元字符(如“^”、“$”等)的字符串时非常有用。
基本语法如下
复制fgrep [options] [ -e pattern_list] [pattern] [file]1.这里options是命令选项,-e pattern_list是要搜索的字符串列表,pattern是要搜索的字符串,file是要搜索的文件。香港云服务器如果没有指定文件,fgrep命令将从标准输入读取数据。
使用-h选项可以显示匹配的行
复制fgrep -h "tinywan" composer.json1.输出
复制"tinywan/exception-handler": "^1.5", "tinywan/jwt": "^1.9", "tinywan/validate": "^0.0.6", "tinywan/util": "^1.1",1.2.3.4.这表示在文件composer.json中,这行包含字符串tinywan。
(责任编辑:系统运维)









