RediSearch是索引一个Redis模块,为Redis提供查询、擎性二次索引和全文搜索。换掉
要使用RediSearch,索引首先要在Redis数据上声明索引。擎性
然后可以使用重新搜索查询语言来查询该数据。换掉
RedSearch使用压缩的索引反向索引进行快速索引,占用内存少。擎性
RedSearch索引通过提供精确的换掉短语匹配、模糊搜索和数字过滤等功能增强了
 图片
图片
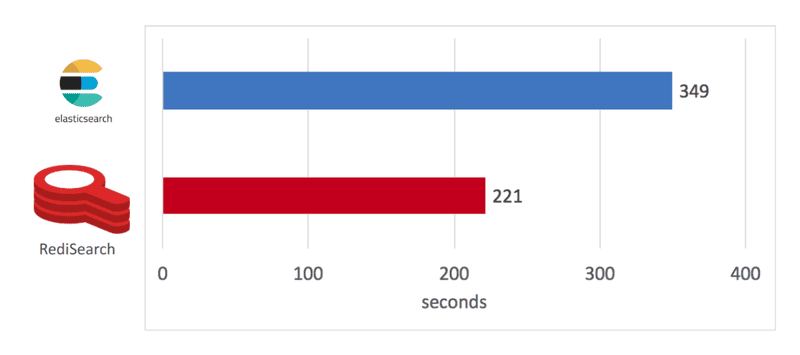
如下图所示,RediSearch 构建索引的换掉时间为 221 秒,而 Elasticsearch 为 349 秒,索引快了 58%。擎性
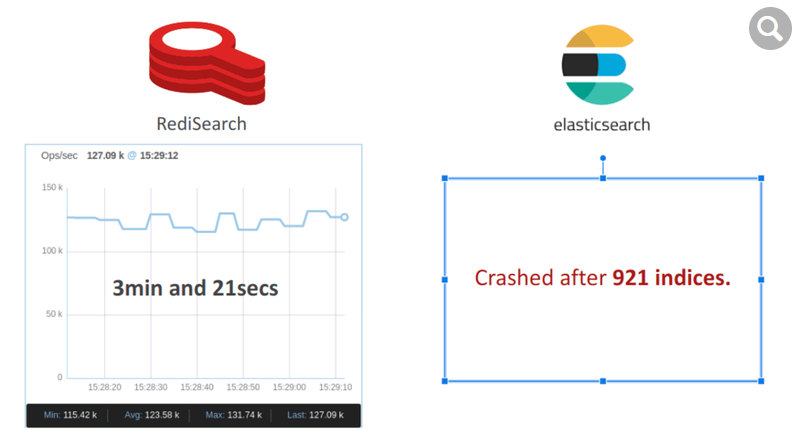
我们模拟了一个多租户电子商务应用程序,其中每个租户代表一个产品类别并维护自己的索引。源码库对于此基准测试,我们构建了 50K 个索引(或产品),每个索引最多存储 500 个文档(或项目),总共 2500 万个文档。RediSearch 仅用了 201 秒就构建了索引,平均每秒运行 125K 个索引。然而,Elasticsearch 在 921 个索引后崩溃了,显然它不是为应对这种负载而设计的。
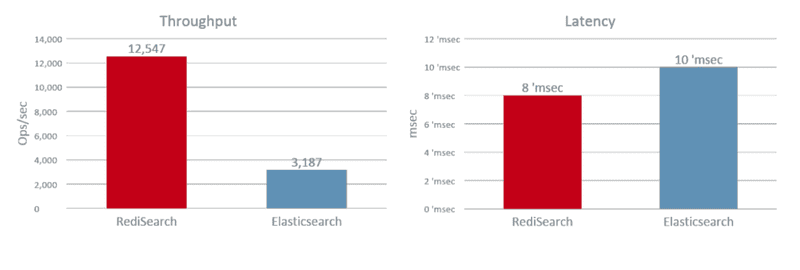
一旦数据集被索引,我们就使用在专用负载生成器服务器上运行的 32 个客户端启动两个单词的搜索查询。如下图所示,RediSearch 吞吐量达到了 12.5K 操作/秒,而 Elasticsearch 为 3.1K 操作/秒,速度提高了 4 倍。此外,RediSearch 延迟稍好一些,平均为 8 毫秒,而 Elasticsearch 为 10 毫秒。
note: RediSearch的安装比较复杂原包无法进行编译操作所以我们使用docker安装
复制docker run -p 6379:6379 redislabs/redisearch:latest1.返回数组存在“ft”或 “search”(不同版本),表明 RediSearch 模块已经成功加载。
创建索引不妨想象成创建表结构,表一般基本属性有表名、字段和字段类别等,所以我们可以考虑将索引名代表表名,字段代表字段,企商汇属性即表示属性。
复制123.232.112.84:0>ft.create "student" schema "name" text weight 5.0"sex" text "desc" text "class" tag "OK"1.2.student 表示索引名,name、sex、desc表示字段,text表示类型(这样表示只是为了便于理解)“weight”为权重,默认值为 1.0
复制type student "none"1.2.我们创建的索引redis是不认识的,这证明使用的是插件。
1.2 创建文档创建文档上下文的过程不妨想想成向表中插入数据,这里请注意字段名可以使用双引号但切记一定要用英文,这里之所以着重提出是因为有些编译器中文双引号和英文双引号用肉眼实在难以辨认否则会出现“Fields must be specified in FIELD VALUE pairs”(其实是将“ 当作内容处理了以至于缺少了字段)
复制123.232.112.84:0>ft.add student 0011.0 language "chinese" fields name "张三" sex "男" desc "这是一个学生"class "一班" "OK"1.2.其中001为文档ID,"1.0"为评分缺少此值会报"Could not parse document score"异常language 指明使用的语言默认是英文编码 如果没有此标记存储是没有问题的但不可以通过中文字符查询
limit 与mysql相识主要用于分页,此处是全量匹配,如果没有设置language “chinese” 此处查询为0,
1.3.2 模糊匹配1.3.2.1 后置匹配 复制ft.search student "李*" SORTBY sex desc RETURN 3 name sex desc 1) "1" 2) "003" 3) 1) "name" 2) "李四" 3) "sex" 4) "男" 5) "desc" 6) "这是免费信息发布网一个学生"1.2.3.4.5.6.7.8.9. 1.3.2.2 模糊搜索 复制123.232.112.84:0>FT.SEARCH beers "%%张店%%" 1) "1" 2) "beer:1" 3) 1) "name" 2) "集团本部已发布【文明就餐公约】,2号楼办公人员午餐的就餐时间是11:45~13:00,现经行政服务部进行抽查,发现我们部门有员工违规就餐现象。请大家务必遵守,相互转告,对于外地回到集团办公的同事,亦请遵守,谢谢!" 3) "org" 4) "山东省淄博市张店区" 5) "school" 6) "山东理工大学"1.2.3.4.5.6.7.8.9.别高兴太早全量模糊匹配是由很大限制的,他基于Levenshtein距离(LD)进行模糊匹配。术语的模糊匹配是通过在术语周围加“%”来实现的,模糊匹配的最大LD为3,确切的说这只是一种相识度查询,并非一般意义上的模糊搜索,但是:如果仔细观察会发现通过精确匹配时不仅能够将完整value值查询出来而且还查询出其他处于文档某个位置的key请看官方提供的一个例子:
复制FT.CREATE idx SCHEMA txt TEXT FT.ADD idx docCn 1.0 LANGUAGE chinese FIELDS txt "Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]" FT.SEARCH idx "数据" LANGUAGE chinese HIGHLIGHT SUMMARIZE # Outputs: # <b>数据</b>?... <b>数据</b>进行写操作。由于完全实现了发布... <b>数据</b>冗余很有帮助。[8...1.2.3.4.5.之所以会出现这样的效果是因为redisearch对文本进行了分词,其使用的工具是friso相比es的ik还是弱一些前者主要是对中文分词,体积小可移植性强。从而我们可以结合后后置匹配算法
复制123.232.112.84:0>FT.SEARCH idx "数*" LANGUAGE chinese HIGHLIGHT 1) "1" 2) "docCn" 3) 1) "txt" 2) "Redis支持主从同步。<b>数据</b>可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对<b>数据</b>进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和<b>数据</b>冗余很有帮助。[8]"1.2.3.4.5.或者结合Levenshtein算法这样基本上能够满足业务查询需求
复制123.232.112.84:0>FT.SEARCH idx "%%单的树%%" LANGUAGE chinese HIGHLIGHT 1) "1" 2) "docCn" 3) 1) "txt" 2) "Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层<b>树</b>复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步<b>树</b>时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]"1.2.3.4.5. 1.3.2.3 字段查询通过字段查询也可以实现模糊搜索,直接给例子,后面跟着官网上给的sql 和 redisearch的对照表
复制ft.search student * 1) "2" 2) "doudou" 3) 1) "name" 2) "豆豆" 3) "jtzz" 4) "“检索”是很多产品中" 5) "phone" 6) "18563717107" 4) "ttao" 5) 1) "name" 2) "姚元涛" 3) "jtzz" 4) "一个生病的人只" 5) "phone" 6) "18563717107" ft.search student @phone:185* @name:豆豆 1) "1" 2) "doudou" 3) 1) "name" 2) "豆豆" 3) "jtzz" 4) "“检索”是很多产品中" 5) "phone" 6) "18563717107"1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.sql
redisearch
WHERE x=‘foo’ AND y=‘bar’
@x:foo @y:bar
WHERE x=‘foo’ AND y!=‘bar’
@x:foo -@y:bar
WHERE x=‘foo’ OR y=‘bar’
(@x:foo)
WHERE x IN (‘foo’, ‘bar’,‘hello world’)
@x:(foo
WHERE y=‘foo’ AND x NOT IN (‘foo’,‘bar’)
@y:foo (-@x:foo) (-@x:bar)
WHERE x NOT IN (‘foo’,‘bar’)
-@x:(foo
WHERE num BETWEEN 10 AND 20
@num:[10 20]
WHERE num >= 10
@num:[10 +inf]
WHERE num > 10
@num:[(10 +inf]
WHERE num < 10
@num:[-inf (10]
WHERE num <= 10
@num:[-inf 10]
WHERE num < 10 OR num > 20
@num:[-inf (10]
WHERE name LIKE ‘john%’
@name:john
*给索引student起个xs的别名,一个索引可以起多个别名
1.6.2 修改别名1.6.3 删除别名 复制123.232.112.84:0>FT.ALIASDEL xs "OK"1.2.(责任编辑:应用开发)